I recently read yet another article from someone who does not believe that electric vehicles (EVs) will have any significant impact on the auto industry or help much in reducing CO2 emissions. He proceeded to walk out several weak arguments to support his theory. While I will go into these arguments in more detail, I want to make it clear that I'm not responding to this article specifically. I'm addressing the misguided ideas in general. I believe these misconceptions are fairly widely held by people who think of electric cars as toys that have no hope of becoming a real force in the market, and they justify their reasoning with outdated information that has become irrelevant or has long since been proven flat out wrong.
The article in question was written by Jason Perlow as a response to Matthew Inman (a.k.a. The Oatmeal) and his
awesome, over-the-top review of his new Tesla Model S. I take Mr. Perlow at his word when he says that he is concerned about climate change and wants to see the most efficient and practical technologies adopted to alleviate the dangerous trends we're seeing in the environment. But then he trots out these tired old saws:
However, what I think has been lost in all this positivism and blind
futurism about EVs and Tesla is how unrealistic electric cars still are
for the average family.
Not only that, but they do not fundamentally solve the problems of
moving to more sustainable energy sources; nor are they particularly
"greener" or less fossil-powered than their gasoline, diesel, or even
hybrid cousins.
These statements get at the three main criticisms of EVs: high cost, short range, and dirty energy source. Assuming that the current state of these issues for EVs will remain constant, or even improve only slowly, betrays a serious lack of vision and judgement. People who think like this must think, "Well, EVs have been widely available for two full years now. Why can't they go for 600 miles on a charge, pull electrons out of the sky, drive autonomously, sprout wings, and fly? Oh, and they shouldn't cost more than a used, stripped down Honda Civic."
Seriously, EVs have only had significant research and development investments in the last decade or so, yet they are advancing amazingly quickly. ICE cars, on the other hand, have had over a century of enormous capital investment, and they're struggling to achieve minor performance and efficiency gains. Let's take a look at the cost and range issues, because they're related, before tackling the more involved issue of how green EVs are and will be.
Choose Low Cost or Long Range, For Now
EVs are primarily electronic devices that happen to have some
wheels to make them move. ICE cars are primarily mechanical devices that
happen to have electronic components for sensing and control.
Historically, electronics drop in price much more rapidly than
mechanical devices, so it stands to reason that EVs will quickly drop in price relative to ICE cars.
Batteries are the single most expensive component of an EV,
so if battery costs fall, the
price of the car will fall with it. As battery production volumes increase
(think Gigafactories) and raw material sourcing improves, prices are sure to come down significantly. In fact,
over the 2010-2012 time frame, battery prices fell by 40%, and that trend looks to be continuing or even accelerating.
Batteries are also increasing in energy density by about 7% per year, or
doubling about every 10 years, so they're getting smaller and lighter in addition to getting cheaper.
Nissan is already talking about that trend with a
Leaf that has double the current range slated for 2017. They also claim that battery energy density is improving much faster than anticipated, so range improvements will likely be coming much faster than their six year model cycle.
One way to think about EVs is that they are like computers. Back in the 80s and 90s, computers were expensive because they were advancing rapidly and companies were focusing on grabbing performance gains. Most reasonably powerful computers sat in the $2000-$3000 range. By the 00s, you could get more than enough power for most uses, and prices started to drop precipitously. Now you can get a ridiculously powerful computer for less than $1000, and even $500 will get you more computer than you need in most cases.
EVs are solidly in the first phase right now where they can add range while keeping the price constant, or they can drop the price while keeping the range constant if there's enough of a market for the lower range cars. Once they achieve adequate range at a low price, it's going to look like the 00s all over again. The other main components of EVs - the motors, inverters, chargers, and regenerative brakes - will also contribute to falling costs as they are standardized and mass-produced.
That's not to say that all EVs are expensive even now. Already there are many different options serving different customers. Want a mid-sized car for tooling around town or as a second commuter car? There's the Nissan Leaf S for less than $20k. Want more range for longer trips, but most trips are less than 40 miles? There's the Chevy Volt for about $28k. Want more luxury and possibly extended range for longer trips? There's the BMW i3 for about $38k. Want to go balls to the walls and price is irrelevant? There's the Tesla Model S for $65k-$110k+. (All prices are after the federal tax credit.)
(
Update: I, of course, forgot to mention the gas savings. The EPA estimates savings of about $9,000 over five years versus the average (23mpg) gasoline car. This assumes 45% city and 55% highway driving at 15,000 miles per year. Your mileage will vary substantially, but you can customize the estimate on fueleconomy.gov to see what you would save. Regardless, it's significant, and makes the already affordable EVs look even better.)
There are more options out there, but those seem to be the big four right now. New models are coming out every year to fill different market holes and increase consumer choice. And then there's Tesla. Tesla is disrupting the industry, and other manufacturers are forced to respond. If Tesla does the same thing to the average consumer market that
they're doing now to the luxury market, they will dominate most of the auto market within the next 5-10 years. Nissan, GM, and BMW are racing to get EVs ready in time to compete with Tesla's mass market EV (
formerly the Model E) before it's too late. The other auto manufacturers are taking notice, but if they don't step up soon, they're going to miss out big time.
When people say that EVs have a huge technical hurdle to overcome, and will only become viable
if they can solve these problems, they are being disingenuous at best. These technical problems are being solved as we speak. EVs are already better than ICE cars in the luxury segment and as an everyday commuter car. Within a few years EVs will meet or beat ICE cars on most metrics. Within a decade they will be far superior to ICE cars in nearly all cases. The detractors are choosing to ignore these obvious trends because they can't seem to envision a world where everyone is driving around in fun, quiet electric cars.
How Green Is An EV, Really?
EVs have to be charged up with electricity, and that electricity comes from a variety of sources. Mr. Perlow presents a graph produced by the US Energy Information Administration (EIA) that predicts rising electricity generation from natural gas and renewables, while the use of nuclear and coal electricity generation stays flat.
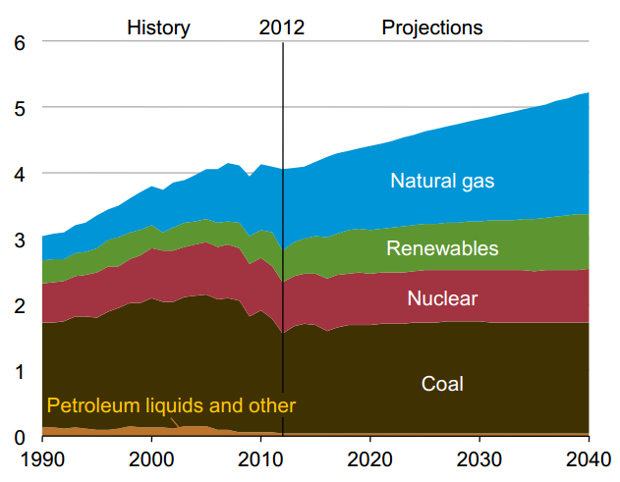 |
| Projected electricity generation by fuel, 1990-2040 (in trillions of
kilowatt-hours). Source: United States Energy Information
Administration, May 2014 |
The interesting thing about the graph is the sharp drop in coal use for the five years leading up to the last year of data in 2012. Why won't that continue? What is causing the prediction to run flat instead of plummeting to zero by 2025? What would this chart have looked like in 2005 at coal's peak? That last question is easy to answer. Here's a chart from the EIA produced ten years ago.
This chart shows coal-based electricity generation heading well north of 3 trillion kWh by 2030, while the latest prediction has coal staying below 2 trillion kWh through 2040! What happened? Natural gas mostly, but also renewables. The prediction from 2004 is clearly wildly off-base even ten years out, and totally useless for a 25 year outlook. Also consider that the energy sector is in a state of flux now, and things are going to change drastically over the next few decades. Using any predictions right now to make claims about the state of electricity generation in 25 years is probably ill-advised.
Long-term predictions are largely irrelevant, but one thing seems to be obvious. Nuclear power isn't progressing much, yet Mr. Perlow promotes nuclear electricity generation as the option to focus on. The problems with nuclear power are numerous. Nuclear plants are extremely capital intensive and take a long time to develop. Nuclear fuel is a very limited resource that's hard to get and expensive to refine. Maintenance of nuclear plants is expensive, and critical to public safety.
These are all difficult problems, but the most difficult problems to overcome are the sociopolitical ones. No one wants a new nuclear power plant in their back yard. Period. Need I mention Fukushima? Then there's the problem of guarding the nuclear fuel before, during, and after using it. The government absolutely does not want terrorists getting their hands on uranium and plutonium, even if it's not weapons grade material.
Why not spend all of that time and capital building solar fields, wind farms, geothermal plants, and other renewable energy sources for much less risk? They scale much better than nuclear, and especially with solar (another electronic device), the more they scale, the cheaper they get. Due to their variable nature, renewable energy sources are also a great compliment to EVs because EVs provide part of the storage solution for when the sun isn't shining or the wind isn't blowing. Then there's
Solar Freakin' Roadways, solar panels that can replace pavement and are
perfectly aligned with EVs.
The point of all of this is that no matter which way the energy sector goes in the future, it's most likely not going to be coal, so all EVs,
including all those currently in use,
will automatically get cleaner as the electric grid gets cleaner. And for those people that install solar panels or wind turbines, their emissions will drop to
zero. If we manage to eliminate coal and natural gas as electricity generation fuel sources at some point, then
all EVs will have zero emissions. How's that for potential?
But that's the future; what about now? Mr. Perlow makes a curious claim about diesel cars, his personal favorite gasoline alternative: "While they aren't emissions-free by any means, modern diesel car engines
also produce less CO2 when compared with gasoline engines." I'm not sure why people think this is true. I keep hearing it, but I've never seen any proof.
Sure, modern diesel cars are cleaner than they used to be, but when I look at
fueleconomy.gov, my main source for comparing cars for fuel efficiency and emissions, for every fuel efficient diesel car there's a gasoline car with equivalent fuel efficiency and lower emissions. That doesn't even include hybrid cars, which are significantly better than diesels, and EVs, which blow them all out of the water.
Since you can only compare up to four cars on fueleconomy.gov, here's a table with a selection of the best 2014 EVs, hybrids, diesels, and high efficiency gasoline cars in both the luxury and mid-sized segments:
Luxury Car
|
Combined
MPG/MPGe
|
Total Emissions (g/mile)
|
Tesla Model S-85 kWh (NY)
|
89
|
110
|
Tesla Model S-85 kWh (US average)
|
89
|
250
|
Tesla Model S-85 kWh (WI)
|
89
|
310
|
Lexus GS 450h (Hybrid)
|
31
|
357
|
Mercedes-Benz E250 (Diesel)
|
33
|
392
|
Audi A6 (Gasoline)
|
28
|
396
|
BMW 535d (Diesel)
|
30
|
430
|
Mid-sized Car
|
Combined
MPG/MPGe
|
Total Emissions (g/mile)
|
Nissan Leaf (NY)
|
114
|
80
|
Nissan Leaf (US average)
|
114
|
200
|
Nissan Leaf (WI)
|
114
|
240
|
Chevy Volt (NY)
|
37/98
|
170
|
Chevy Volt (US average)
|
37/98
|
250
|
Chevy Volt (WI)
|
37/98
|
290
|
Toyota Prius (Hybrid)
|
50
|
222
|
Toyota Corolla (Gasoline)
|
35
|
317
|
VW Passat (Diesel)
|
35
|
368
|
I loosely sorted them by lower emissions first, but kept each model of EV together. The EVs have three entries corresponding to different electricity generation fuel mixes in different areas of the country. I picked a best-case scenario of New York state, the US average, and my home state of Wisconsin, which has a fairly dirty fuel mix of mostly coal-fired plants. If you charge your EV with solar panels or purchase renewable energy offsets (as I do), then your total emissions would be zero.
Notice how the diesel car emissions are worse than all of the other cars, even if the mileage is better. Both the Mercedes-Benz E250 and the BMW 535d get better mileage than the Audi A6, but the A6 emissions are essentially the same as the E250 and 8% lower than the 535d. The Lexus hybrid's emissions are 10% lower than the E250, and the Tesla's emissions are nearly one quarter those of the E250 on New York state electricity.
On the mid-sized car side, the Toyota Corolla has 14% lower emissions than the VW Passat with equivalent fuel efficiency, and the Prius just crushes the Passat with 40% lower emissions. The Prius competes rather well with the Nissan Leaf and Chevy Volt over the average mix of US electricity, but it's no contest if the EV and PHEV are in clean electricity areas. The Leaf has nearly three times less emissions than the Prius and 4.6 times less emissions than the Passat!
I really don't understand why people want to buy diesel cars. They're more expensive, and the fuel is more expensive than an equivalent gasoline car. There's a wide selection of gasoline and hybrid cars that are just as, if not much more, fuel efficient than diesel cars so there's no fuel cost savings there. It's more difficult to find fuel because not every gas station offers diesel. And they still have higher emissions than many gasoline, most hybrid, and all electric cars. Diesel is not a viable alternative clean fuel. EVs and PHEVs are already hitting dramatically lower emission levels, so there is no need for an interim technology anyway.
The Real Reason EVs Will Dominate
The main arguments against electric cars are range, cost, and dirty electricity source, but these are all largely overblown or only issues
right now. EVs are not standing still; not by a long shot. Every year they are improving significantly with no end in sight. Detractors that point to the state of EVs this year or last year and try to extrapolate that into claims about how they'll never work out are either being short-sighted or naive. The disadvantages are just engineering problems to be solved, while the advantages are fundamental, and the advantages of EVs -
much better
comfort and
convenience - are things with which no ICE car can compete.
People love comfort and convenience. Most of the choices we make that are not directly related to basic needs center around maximizing comfort and convenience. EVs go a long way to improving both of those things.
EVs are super quiet with silky smooth acceleration and are really fun to drive. Then when you're done with your comfortable drive, you can pull into your garage, plug in your car, and you'll be all juiced up for the next day. That means no runs to the gas station
ever again. Oh, and there's also the convenience of
nearly zero maintenance. That's why EVs will finally beat the ICE car. I say good riddance.
